Improving performance with partitions
In the last post: Database Performance Tuning, we saw how applying an index can greatly improve query performance. But what happens when a table already has all the possible indexes and performance is still not as good as we want?
EDH Order Images
The EDH orderimages table contains details about an order from Qualiac and a copy of the full text of the order stored as a LOB. There are indexes on each of the common fields: supplier, technical contact, created date, etc… and a context index on the LOB used to support keyword searches from the EDH search form. The table contains ~1’300’000 rows going back to 1993, with approximately 50’000 documents per year.
Order search performance is not terrible, on average searches complete within 2 seconds, the search does show up occasionally in the top 10 slowest requests with 99th percentile queries taking 20-30s to complete.
Which index to use?
The orderimages table contains indexes on all of the columns used in the order search. So why is performance still suffering? One limitation of b-tree indexes is that they cannot be combined*. Consider the query:
select * from orderimages where fou = :supplier and dat >= :created
Using the statistics the database engine regularly gathers on the distribution of each column, it will decide whether to use the index on fou OR dat based on which would result in the fewest results, and then filter based on the second criteria.
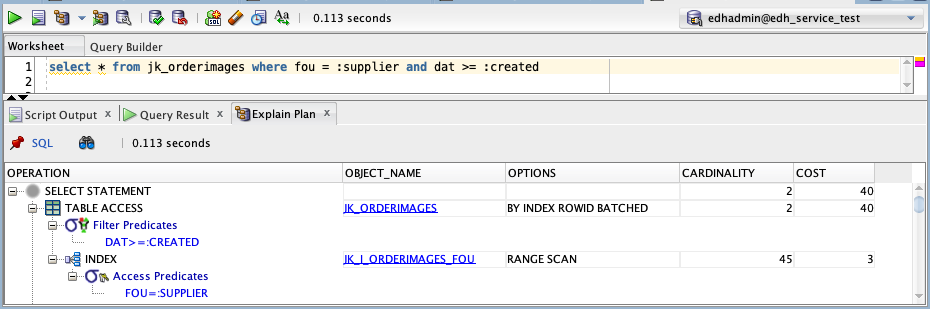
Here the database uses the fou index and then filters the results by dat. This is not ideal since we need to maintain multiple indexes but only one of them will actually be used. Especially since the table contains data since 1993 and users usually don’t want documents created so long ago.
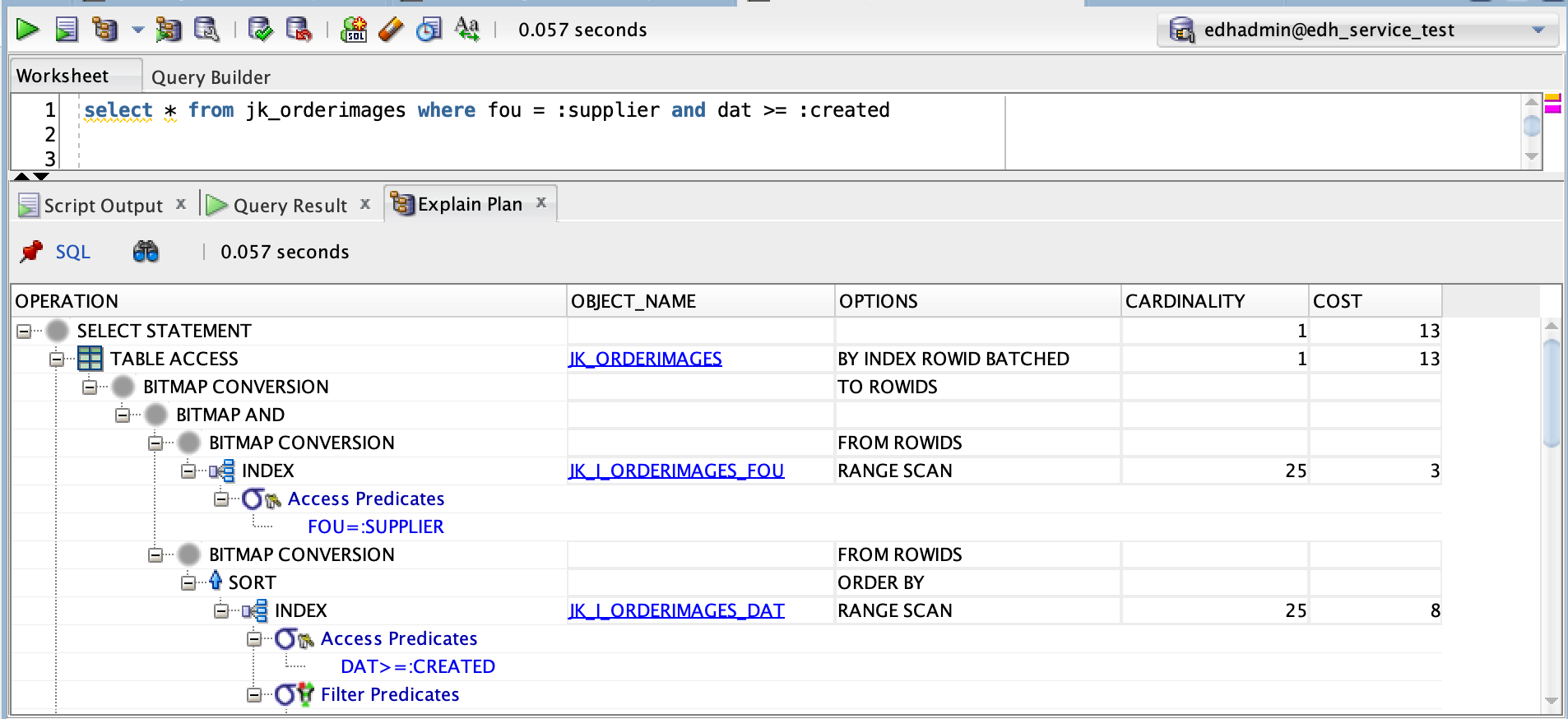
*Note: bitmap indexes can be combined and sometimes the database engine may decide that it is more efficient to convert the b-tree index to a bitmap index, combine the resulting indices and then access the table. In this example, the table test table only contains data from 2018-01-01, which means performing the bitmap conversion is not too expensive.
Partitioning to the rescue
When a table contains a large amount of data, partitioning may be a suitable technique to break the table in to smaller, more manageable pieces. Partitioning can be useful if there is a business date related to the data, such as date created, or a classifier such as job name or type, that is used to access and reason on the data.
Partitioning allows tables, indexes, and index-organized tables to be subdivided into smaller pieces, enabling these database objects to be managed and accessed at a finer level of granularity. - Partitioning Concepts
One of the benefits of partitioning is the the ability for the database engine to perform partition pruning. That is, if the query contains a clause that limits the results to fixed set of partitions, the database only needs to consider those partitions and associated local indexes. Reducing the amount of data that needs to be loaded by the engine to fulfill the query.
If we partition the orderimages table by dat, the engine can make use of partition pruning to reduce the number of data blocks accessed. With a local index we may even see improved performance when performing a range scan since the the index of each partition is smaller.
To compare the results of partitioning on our query, we can run the query with Autotrace, which gives the estimated cost as well the actual cost in elapsed time and buffers read.
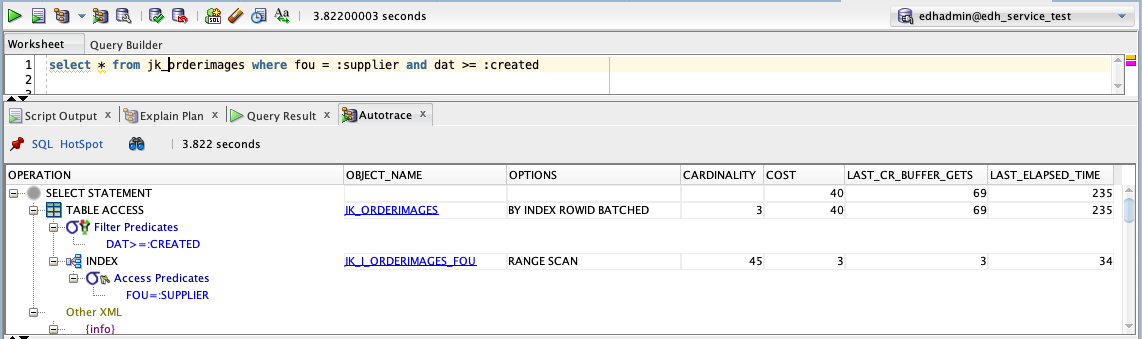
The explain plan for the query on the partitioned table shows some new information: the partition_start and partition_stop points. These indicate which partitions will be read during the query. Since the query is parameterised, the value is KEY instead of an actual number. The end partition is known to be 25 since there is no upper bound on dat in the query and the table contains 25 partitions.
Comparing the estimated cost of these 2 plans, we might think that since 49 > 40, the non-partitioned version is better. However, when checking the buffer gets and elapsed time we see the partitioned query is twice as fast.
The catch
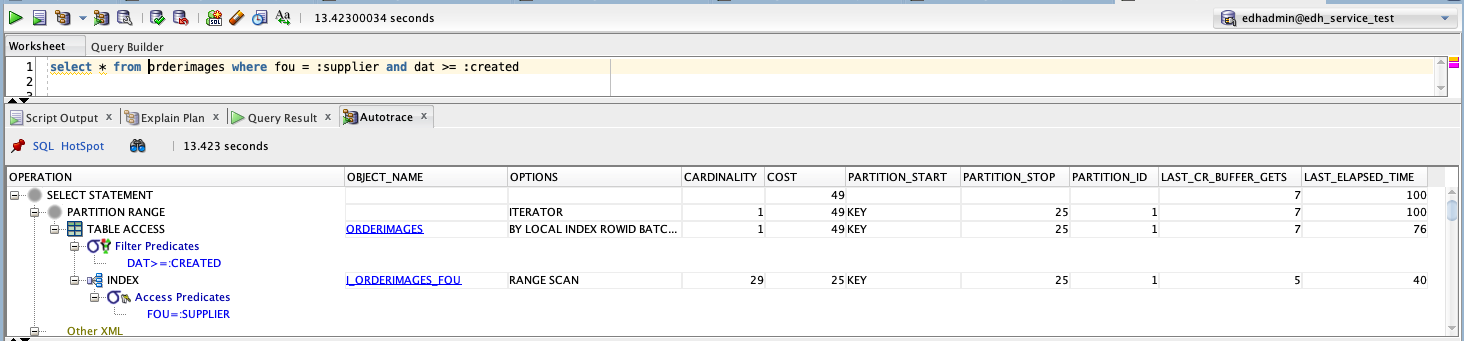
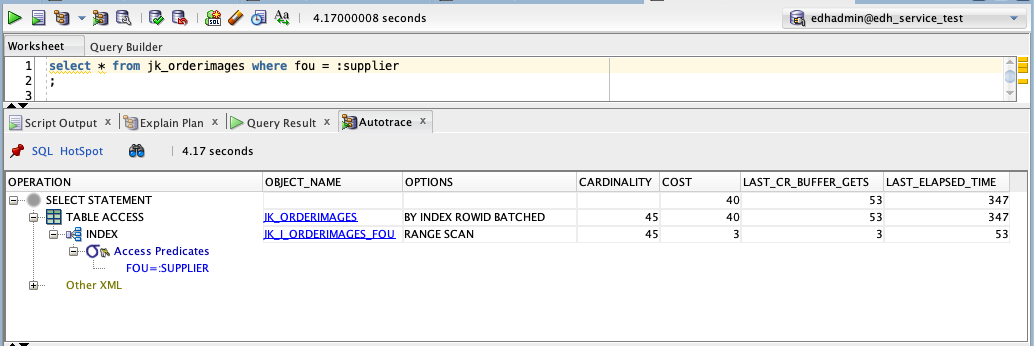
Partition pruning is only possible if the query filters on the partition key. So what happens if we search only by fou ?
select * from orderimages where fou = :supplier
Without partitioning it is as we might expect, the index is used to find all of the rows that match and they are returned with no additional filtering.
On the partitioned table, the plan is very similar, except we see that the partition start value is 1, and the partition stop value is 25. This means the engine had to check the local index of each partition for matching rows and then retrieve the results from each partition. In this case, the result is worse performance. Depending on the data distribution it may not always be worse, since the indexes of a partitioned table will be more compact and may still result in less buffer reads.
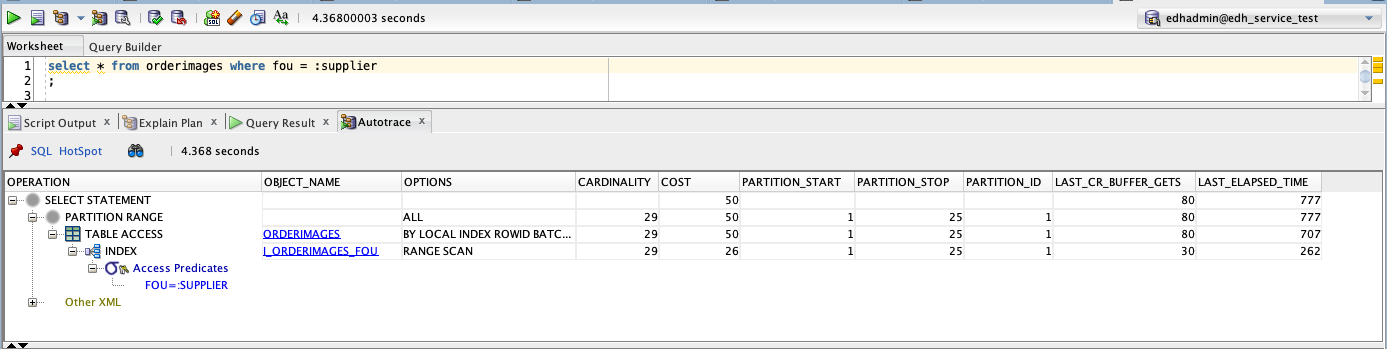
If it is common to access the table without filtering on the partition key, a global index could be used instead of a local index.
h2. Context Indexes
A regular b-tree index on a VARCHAR column will only be used for exact (like ‘:q’) or prefix matches (like ‘:q%’) queries. Full wildcard queries (‘%:q%’) cannot make use of regular indexes.
To perform a contains query, an oracle context index can be used. An Oracle context index splits the indexed document in to tokens, and then stores an index of tokens and a list of documents that contain the token. This makes it possible to search for documents that contain a word/token. Other operations are also possible such as document theming or classifying.
Context indexes are expensive to maintain and require synchronisation after each operation on the indexed table. The syncrhonisation can be scheduled automatically as part of the index definition or triggered via a PL/SQL procedure.
The contains function is used to query a context index:
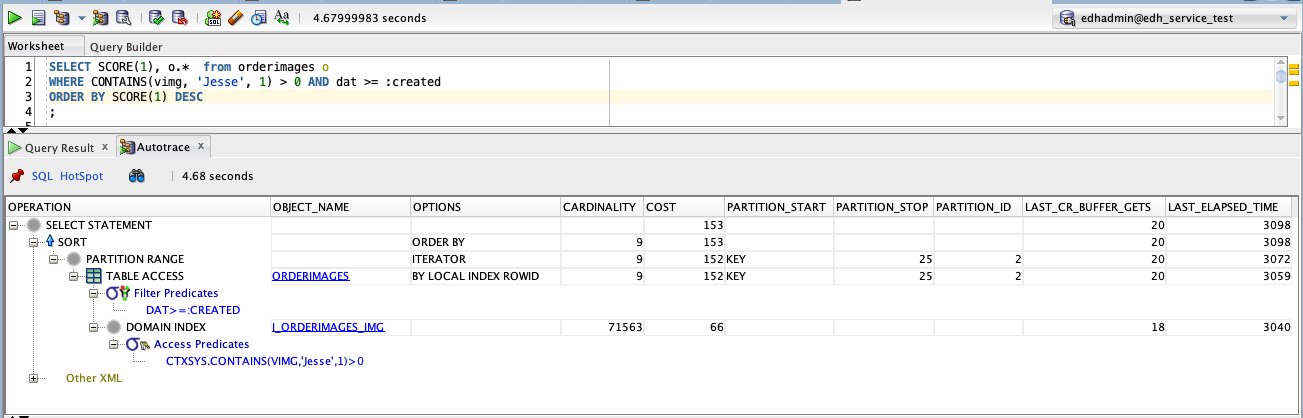
SELECT SCORE(1), o.* from orderimages o
WHERE CONTAINS(vimg, 'Jesse', 1) > 0 AND dat >= date'2020-01-01'
ORDER BY SCORE(1) DESC
;
The query plan shows partition pruning is used and the context index is scanned for results and then filtered by the dat
Maintenance
With a very large table, it can take several hours for the context index to be created. This could result in long periods of unavailability in the event the index becomes corrupted and needs to be rebuilt. With a locally partitioned context index, the partitions containing the most recent data can be rebuilt immediately, quickly* returning availability of search for recent documents. The older partitions can be rebuilt later to return full availability.
After rebuilding the 2020 and 2021 indexes, a user would be able to search all documents created since 2020-01-01, however searching for documents created since 2019-01-01 will fail.
ALTER INDEX I_ORDERIMAGES_IMG REBUILD PARTITION p_2021
;
ALTER INDEX I_ORDERIMAGES_IMG REBUILD PARTITION p_2020
;
*For some definition of quick, it could still take 30 minutes to rebuild a partition depending on the number of documents to index
Results
So has performance improved? It’s difficult to say… the partitioning was applied 22.05.2021. The median response times seem slightly better but there is no clear improvement in the upper percentiles. Could it even be worse?
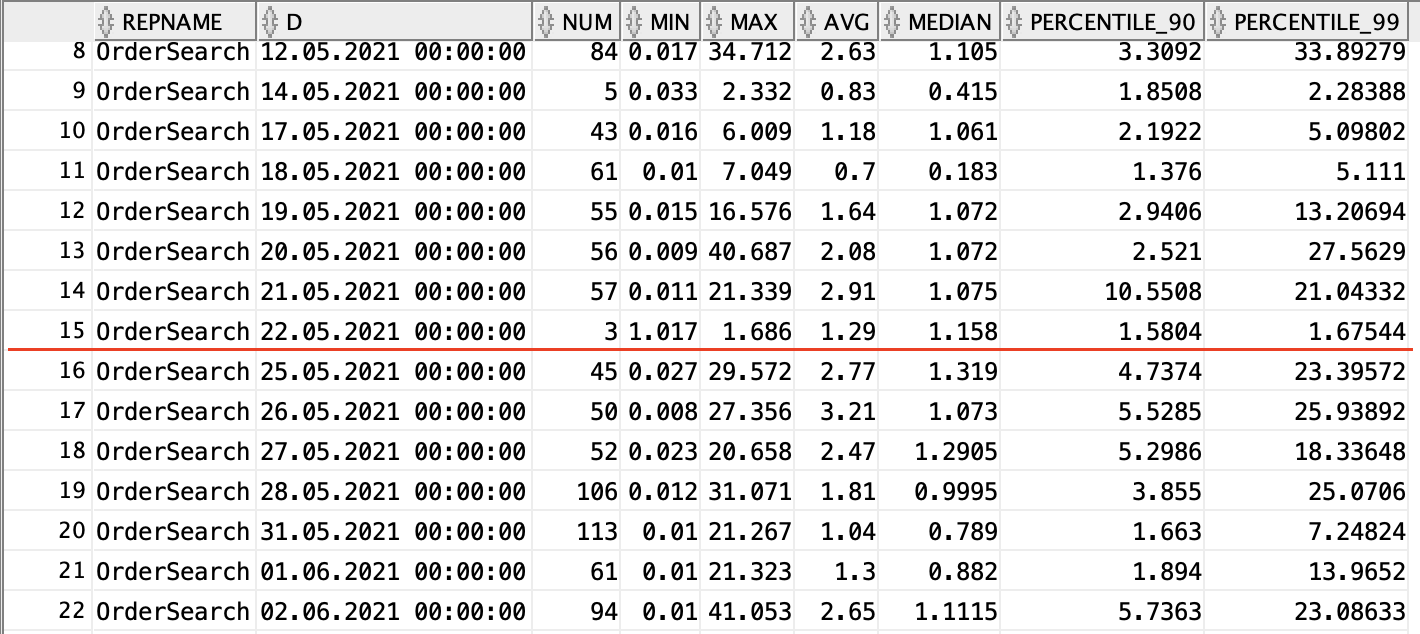
In order to realise any performance gains from partitioning, the search must include a date filter. So what if we check the performance of searches that include a date range:
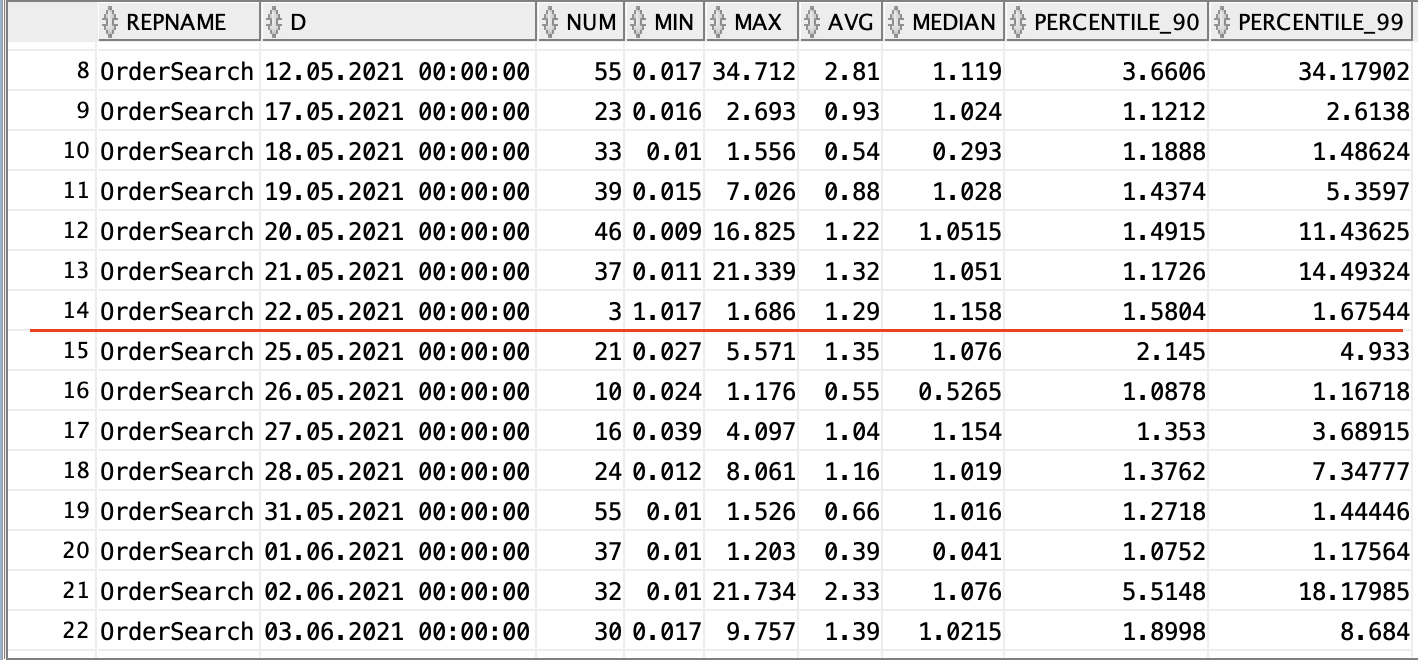
Now we start to see an improvement. The 99th percentile is way down, with the odd search still taking a long time. But why do less than half of searches include a date range? Checking the search form quickly reveals the answer:
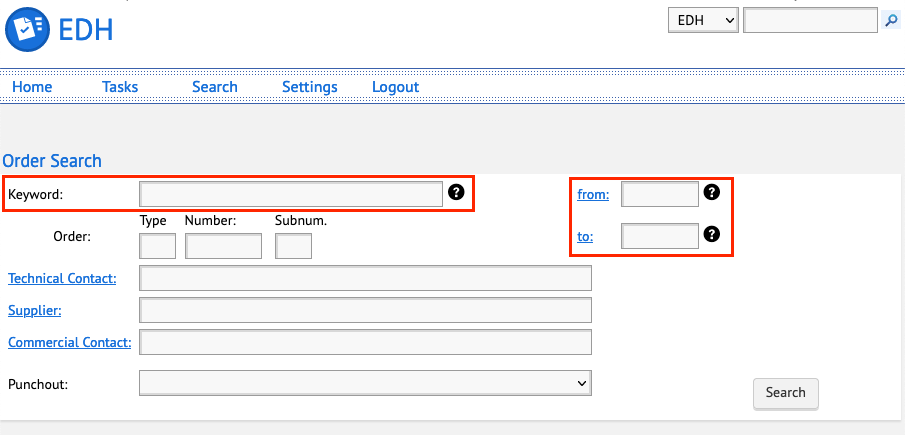
The form encourages users to make the most expensive type of search by placing the Keyword input first, and discourages using a date range by placing the date inputs to the side without a sensible default and requiring the user to manually select a date.
To really improve the performance of order search we would need to change user behaviour. Perhaps by encouraging the use of the more specific and faster filters such as Supplier, and making it easier to select an appropriate date range by using a drop down of some predefined date ranges as is used in the Document Search form.
Conclusion
So was the partitioning worthwhile? I still think yes, the improved maintainability is a huge benefit and users that do use a date filter in their searches will benefit from a faster search. Is partitioning always the answer? Probably not. I would say start with a regular table definition and consider partitioning once you understand well the access and update patterns for the data. The wrong combination of partitioning and querying may not result in performance improvements and could even hurt performance.